Index | About | Computer Project | Files
Computer Project Introduction | Get IDs | Split up IDs | Get Netatmo weather data
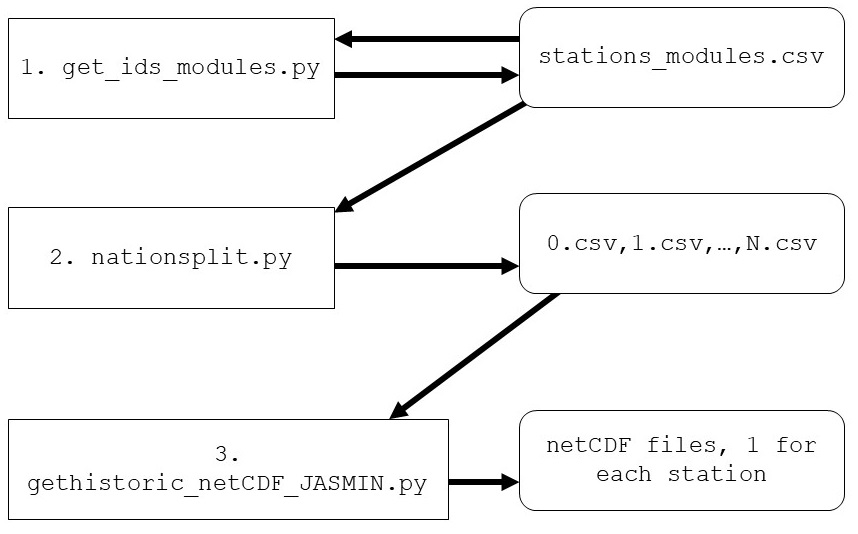
There are three main pieces of code to collect data from Netatmo weather stations:
.csv file containing a list of known Netatmo weather stations. Then, the UK is checked for new stations - if there are any new stations, then these are added to a dictionary before the .csv file is updated.stations_modules.csv file is read, and the stations are split into some 40 files, each containing roughly 250 calls of the API..csv file and creates a netCDF file of every Netatmo weather station's data in the past list.
Requirements
All my code has been written in Python 3(.7.4). To run my code, you need the following core modules and external packages installed. I have included the specific versions I have tested the code on. On the webpage for each separate script, I have included what packages each script requires.
Core modules:
sys library, to use command line inputos, to create directories.datetime for managing dates and times in Python.time for managing times in Python. pathlib, using the Path function for directory management. numpy 1.17.2, for general number-wrangling with arrays.netcdf4 1.5.3, to create and write to netCDF files.requests 2.22.0, which initiates the data retrieval from the Netatmo APIpandas 0.25.1, which is used to read and write .csv files.Some scripts require a Netatmo Developer Account, in order to retrieve data from the API.
Running the scripts
I run the scripts from the command line; I use cron to schedule the scripts to run at the correct time. Specific syntax for each script (i.e. which arguments each script requires) is written at the top of each script.
Background
Netatmo weather stations all upload their data to a data server. Data can be retrieved through the Netatmo Weather API. This data is also displayed on the Netatmo website, via their weathermap. The API has limits for retrieving data: no user may request data more than 50 times in 10 seconds, and no more than 500 calls per hour. The code has been written so that this is avoided. The API has three commands:
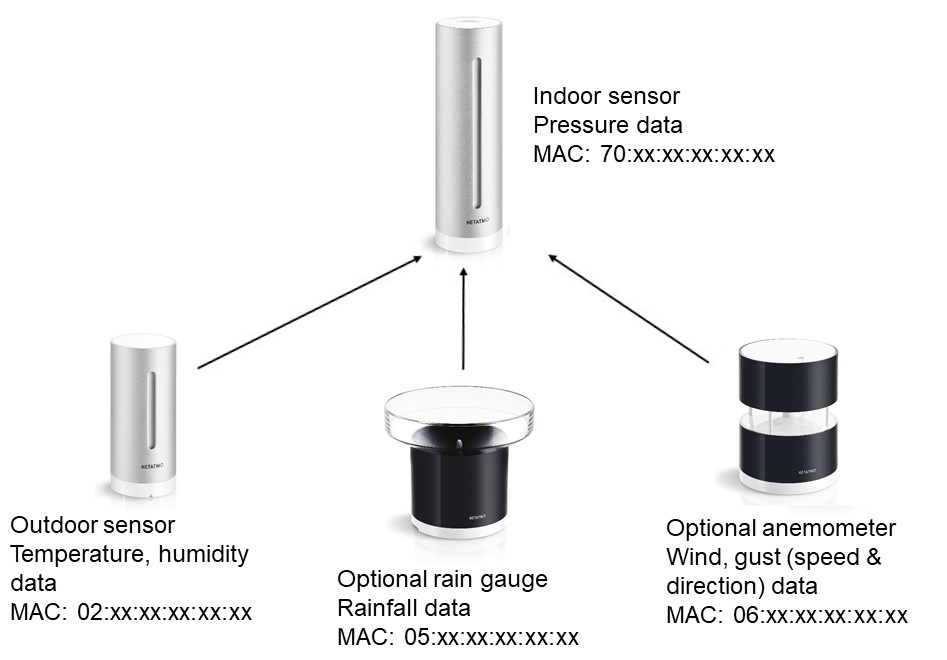
getpublicdata - used to get all "live" data from stations in a given area. getpublicdata also returns the MAC addresses of weather stations, which is useful for the other commands, particularly getmeasure. getmeasure - used to get all data from a given station (using a station’s MAC address & MAC address of module required) within a given time period.getstationsdata - used to get all "live" data from a user's own station, or a station a user has been given explicit permission by the owner to access. This command contains "not for public" information such as indoor temperatures, indoor noise levels.Each Netatmo weather station and component of a weather station has a MAC address (or ID). Accessing data from any part of a weather station requires these MAC addresses. Accessing data from a particular sensor, for example the rain gauge requires the MAC address of both the indoor sensor and the rain gauge, since the outdoor sensors communicate to the Netatmo indoor sensor via Bluetooth before the indoor sensor uploads all the data to the API. My code runs throughout the day, on a batch compute cluster, LOTUS, accessed through JASMIN, a supercomputer run by the Centre for Environmental Data Analysis (CEDA). The LOTUS machine prioritises jobs so that all users get a fair share in the queue so jobs can exit without finishing. Coupled with the limitations of the API discussed above, this code tries to get as much data as possible from observations made the previous day.
Future work will focus on using the data collected to analyse the quality control methods mentioned previously, and to see whether Netatmo weather stations are a reliable source of mesoscale observations. To futureproof the code, and to allow for instances where the script does not capture all stations that it should do (usually to do with issues with JASMIN), a script could be added to check what stations are missing for a particular day and then retrieve this data from the API where possible. However, this may lead into issues with the limits imposed by Netatmo (see above). One possible solution is to act on a 48 hour cycle rather than a 24 hour cycle like the code does currently, and retrieve data from two days at a time rather than one which would free up time for retrieving more data, and error-correcting along the way. Another improvement would be to get weather data in a more "random" way rather than regionally as it does at the minute, to ensure some reasonable UK-wide coverage if LOTUS is not functioning properly for some part of a given day. |
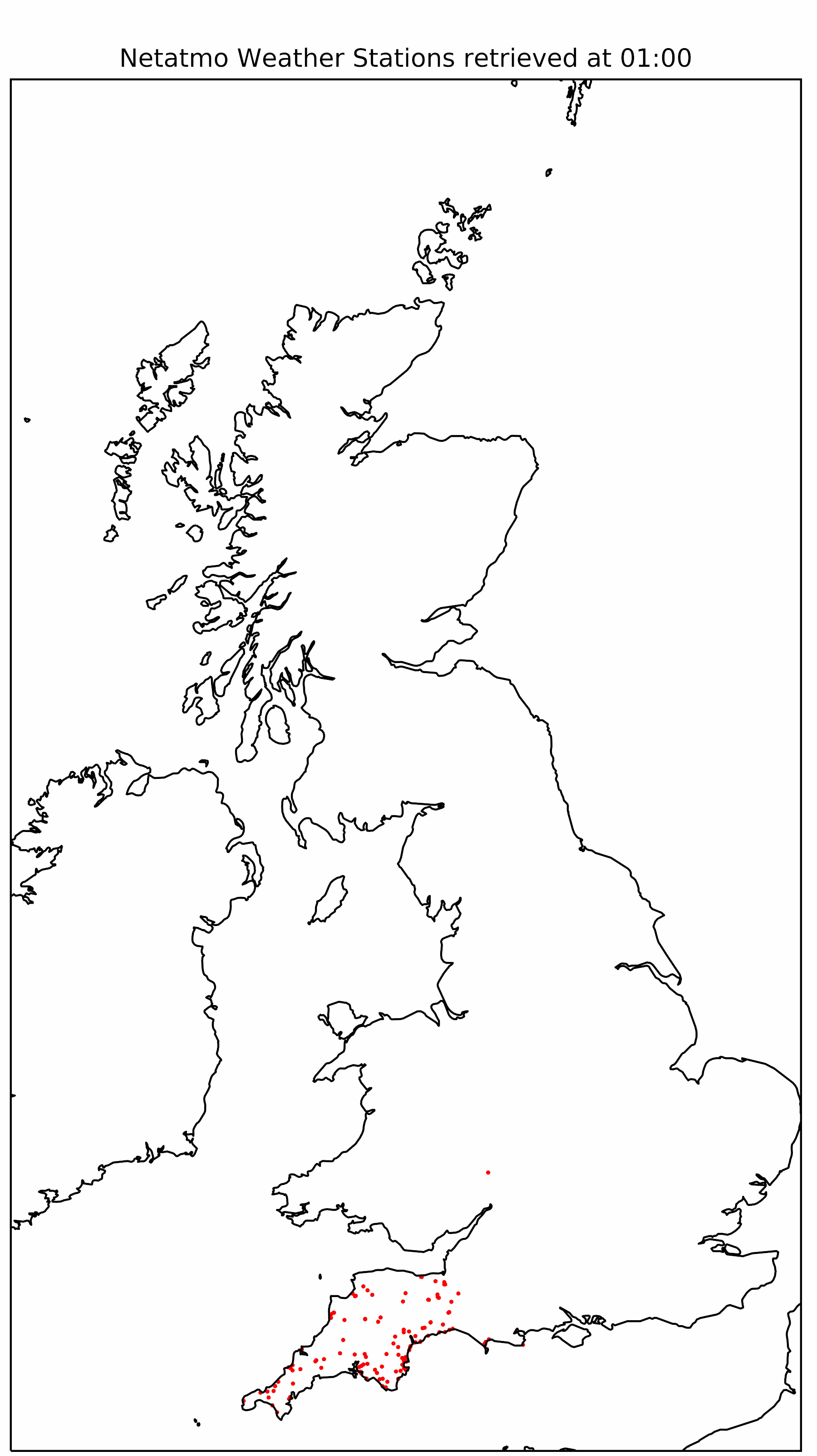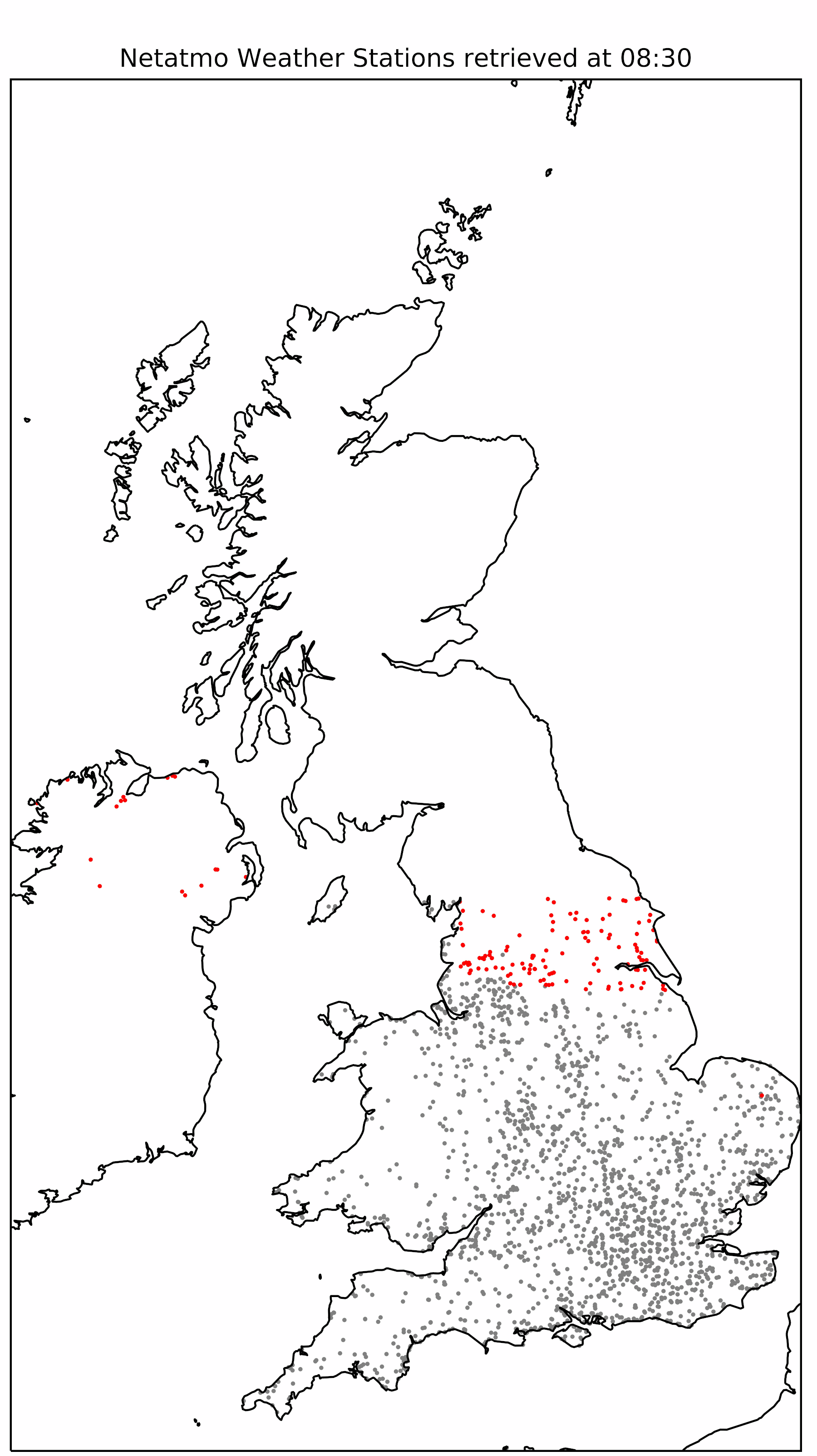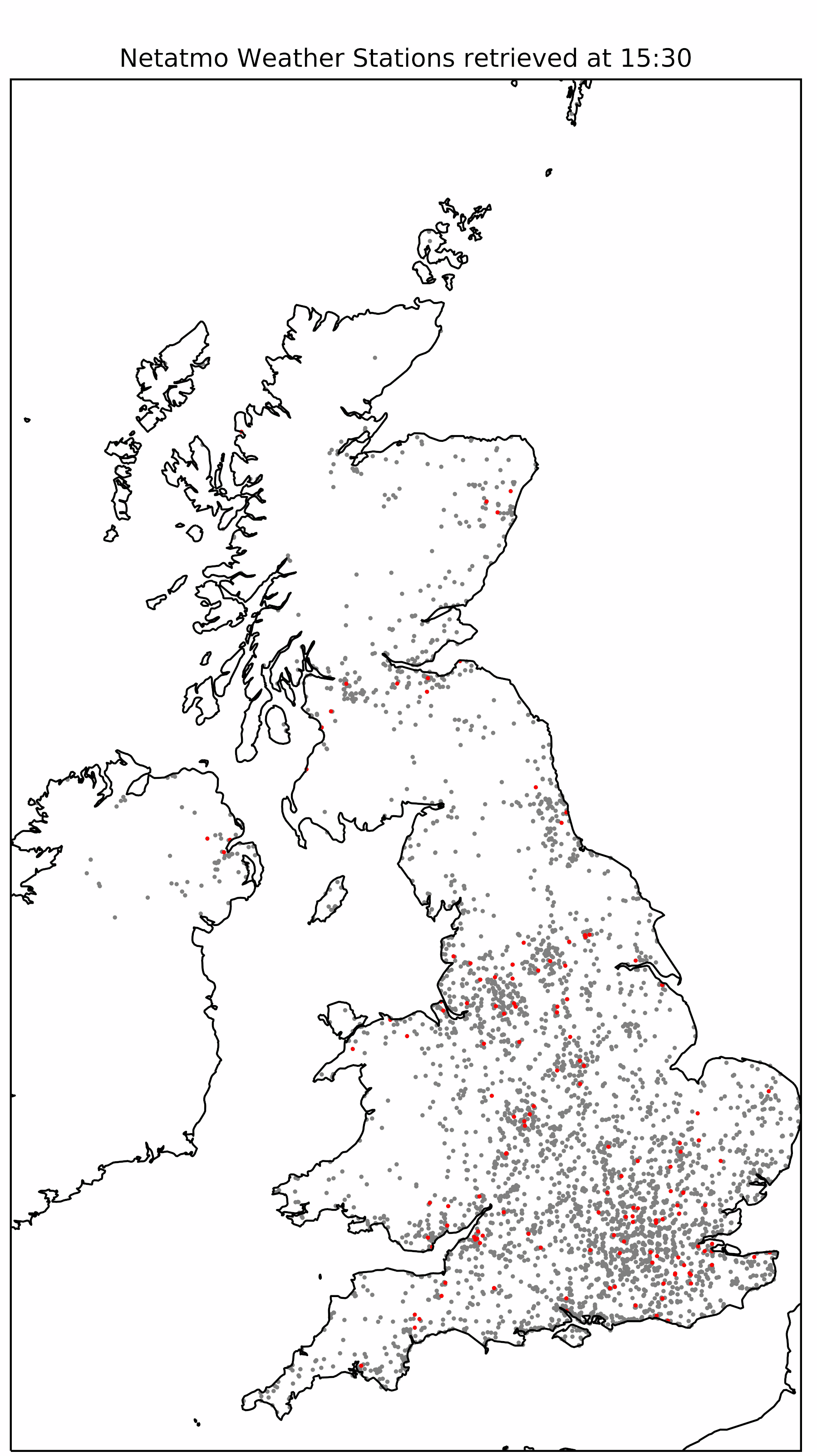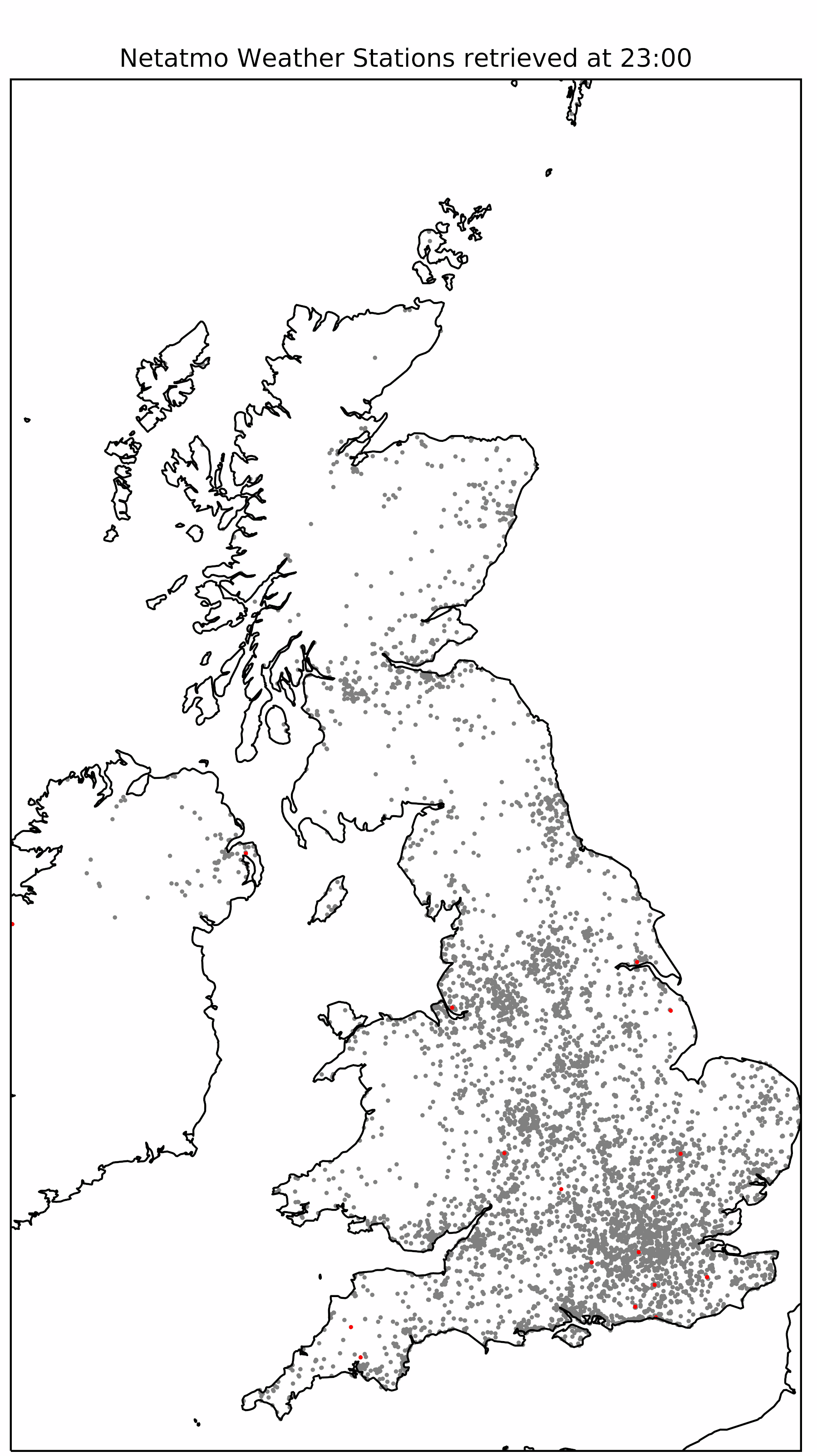
|
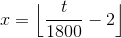 , and t is the number of seconds since midnight. This selects a different
, and t is the number of seconds since midnight. This selects a different